
Large Language Models Can Self Improve: An Implementation Attempt

Last week, I came across a paper called “Large Language Models Can Self Improve” and decided to implement it. It turns out that I was too naive to realize that there is no way that I could have replicated a fraction of the results given my limited budget, computing power, and access to language models. Although my attempt failed, it was incredibly fruitful. I’ve spent ~ 7 weeks on ML so far, and I am planning on spending more time diving deeper into language models. More and more, I started to realize not only the potential in this field but also the potential for everyone to become a self-taught ML expert. It’s difficult, but it’s far from impossible.
In this blog post, I will share my takeaways from my failed attempt to implement a self-improving language model in layman's terms. I hope my humble journey will inspire more people to overcome their fears and embark on their own incredible autodidact journey!!
Glossary
LLM: large language models. They are pre-trained on a large amount of corpus and can perform text-based tasks like generation and prediction on a wide range of topics.
Supervised vs. Unsupervised Learning: Supervised learning use labeled datasets whereas unsupervised learning uses unlabeled datasets. Unsupervised learning discovers hidden patterns in data without human intervention.
Token: In NLP, tokens refer to smaller subunits of texts. These subunits can be sentences, words, or a part of a word.
Completions, Inferences, Generations: They generally refer to the text that is generated and returned as a result of the provided prompt or input into a language model in the context of this piece of writing.
The Problem: LLMs are not the best reasoners
LLMs can surprise you with their ability to converse in Shakespearian language or engage in philosophical conversations, but they are not the best reasoners yet. Even the powerful GPT3 cannot consistently solve 2nd-grade math problems.
Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? A (GPT3 Davinci): In April and May, Natalia sold a total of 96 clips.
GPT2 has even less clue about how to reason.
A (GPT2-XL): Natalia sold 48 clips to her friends in April. She sold 48 - 5 = 34 clips in May. In total she sold 54 clips. The answer is 34.
Improving LLM’s ability to perform logic tasks is difficult. We cannot let LLMs take a creative approach to math problems that only have one correct solution, so we must train the model with labeled data. However, clean, labeled data is limited and costly to obtain. Famous logic & reasoning datasets like OpenbookQA and GSM8K each only have a few thousand labeled question-answer pairs each. This is very limited compared to the tremendous body of text all over the internet that we can use for unsupervised training. Additionally, it’s costly to write and solve a diverse set of logic questions for the sake of creating labeled data. There is also no simple way to capture the data we naturally generate in day-to-day academic activities as we could with Tweets or Wikipedia. [Side note: you’d think online grading platforms like Gradescope are well positioned for this, but as far as I know they don’t have the computer vision technology required to capture data with high accuracy.]
“Large Language Models Can Self-Improve”
This paper by Google Research is exciting because it shows that LLM can improve its performance on logic tasks with unlabeled datasets only. Using the “Chain of Thought” prompting technique and “self-consistency,” LLMs can answer logic problems mostly correctly. We can then pair the questions in the unlabeled datasets with the answers generated by LLM for supervised learning. The paper shows that this approach leads to state-of-the-art performance on logic & reasoning tasks.
Chain of Thought (CoT) improves LLMs’ performance by prompting them to decompose multiple-step logic problems. Self-consistency (alternatively called “majority voting”) asks LLMs to generate many answers given the same prompt and pick the answer that appears most often.

ELI5: The main idea of the paper
Jargons aside, the main idea behind the paper is straightforward. When I tried to explain the paper to my roommate @kristiehuang, we came up with this abstract analogy that explains the gist of the paper.
Imagine a class of second graders that are new to multiplication problems. Each of them can only answer 70% of the problem set correctly, so you decided to help them in two ways:
Write down a few example problems on the blackboard with step-by-step solutions that they can refer to when solving homework questions (CoT).
Facilitate the class to solve problems together. If everyone solves the problem independently and the majority arrive at the same answer, we are pretty confident that the answer is correct, therefore regarding that as the ground truth solution (Self-Consistency).
Once the class finishes solving all the problems together referencing your examples, you use the question-answer pairs in their homework as new learning materials for the students. The paper shows that this process will individually improve their ability to solve problems!

My implementation: Picking Models & Datasets
Multiple logic & reasoning datasets were used in the paper to generate training data sets and evaluate the performance of the LLMs. To reduce scope, I decided to work with only one dataset: GSM8K, around 8k grade school math problems. The paper used Google’s PaLM, which is not accessible to the public. Picking an alternative LLM to work with introduced the first major challenge.
I tried generating training data with CoT and self-consistency using GPT-3’s Davinci (175B parameters) and Curie (6B parameters), and they each only achieved 58% and 5% accuracy on a sample of 100 questions. Curie is obviously not good enough for generating training data sets with high accuracy, and Davinci is also barely halfway there. However, the bigger problem with using just Davinci is that OpenAI currently does not allow us to fine-tune the model. [Side note: I can’t find any information online about what actually happens when you fine-tune a model through OpenAI’s API. However, if it actually updates all the parameters instead of only updating the final layers, it can be costly to store 175B parameters for each fine-tuned customer copy of Davinci. This might be a reason why OpenAI only allows fine-tuning of smaller models, aside from other safety risks.]
One option is to use Davinci-generated training data to fine-tune Curie, and this is how I eventually proceeded with the project. However, I thought it would be really cool to have an LLM generate new training data for itself, so I looked into GPT2-XL (1.5B parameters), which is open source. In hindsight, I would have saved myself lots of time if I knew GPT2-XL would be much less powerful than GPT3 Curie, but this digression actually introduced me to a whole new world: the systems side of ML.
The Systems Side of ML - A Puzzle
How to work with limited memory and computing power? How to write code that can be generalized to different models? These questions are just as important, if not more essential than the algorithms themselves when it comes to training and testing large models.
For example, loading GPT2-XL on Colab free tier crashes RAM regardless of the runtime you’re connected to. However, GPT2-Large works just fine. This is because GPT2-XL has 2x more parameters to load which requires more than the amount of RAM (~13GB) the Colab free tier provides. When I was finally able to load the model with Colab Pro which offers up to ~27GB RAM, I ran into a new puzzle. I was able to use GPT2-XL to generate one or two inferences, but when I ask for 10 completions at once, RAM crashes again.
Working with GPT3 APIs abstracted away lots of details for the end users because the compute is handled by OpenAI’s servers and GPUs. To implement majority voting, I ask Davinci to generate 32 responses at a time by passing n=32 in the API call. This implementation is less costly and more time efficient than having a for loop that loops 32 times. This API call generates 32 responses in the same time it takes to generate 1. Since OpenAI charges for API usage based on the total amount of tokens in the prompt and responses, this approach also makes sure the prompt you pass in only gets counted once instead of 32 times. Without understanding what happens under the hood, it seemed to me that it’s only beneficial to ask GPT2 to generate 32 responses at a time as well. Why did it fail?

I was only able to solve the puzzle after reading “Attention is All You Need” to understand the architecture of transformers, the architecture employed by GPT-3. With the help of my friend @realgmittal, I realized that to compute self-attention, we need to multiply Q with the transpose of K; Q and K each have dimension (N, d), with N being the number of tokens in the input, and d being the dimension of query and key vectors that we define. The result of the matrix multiplication has a size (N, N), which bounds the memory complexity required. So when I fed GPT2-XL a very long prompt using the CoT technique, the memory required to materialize this calculation would increase quadratically. Furthermore, when I ask for 32 completion at once, Q and K are now each (32, N, d) in size as opposed to (1, N, d) - we basically stack up 32 matrices of the size (N, d) and compute matrix multiplication for Q and K at each “layer” independently and simultaneously. This parallelization is exactly why it takes around the same amount of time to compute multiple responses as it takes to generate one response. However, this also means that the resulting matrix is of size (32*32, N, N), which requires 1024x GPU memory space in comparison. That is exactly why memory crashed!
To be honest, concepts like GPU, CPU, RAM, threading & parallelization are still abstract to me at this moment. Until I actually spend time understanding what happens under the hood, I will probably be continuously confused. As a beginner, I found systems problems quite difficult to address for a few reasons:
It’s costly to obtain compute resources in order to actually learn how to work with GPUs
There’s a limited amount of practical resources on the system side of ML compared to the algorithm side
Blog posts and stack overflow answers become inaccurate over time due to changes and updates in GPUs and cloud GPU services. For example, a model might be able to run on Colab free tier in 2020, but might not be able to do so now due to the recent Colab update.
If you have advice on how to obtain sufficient working knowledge for the system side of ML, please let me know!!
A Summary of My Progress
I wrote the pipeline for evaluating any GPT-3 models on GSM8K (standard prompting, CoT prompting, and CoT + self-consistency) here and the pipeline for generating training data via CoT and majority voting here.
Applying CoT and self-consistency techniques as described in the paper on Davinci was only able to generate correct answers to 58 out of 100 randomly sampled GSM8K questions. Using these completions as training data would introduce lots of noise in the fine-tuning process. Therefore, I implemented something that’s not directly implemented in the paper: a confidence cutoff. Only if k out of 32 generations arrive at the same answer do we include the n completions as part of the training set. By choosing k=20, I was able to bump the accuracy of the training data set to ~89%. Setting k= 26 would probably result in an accuracy of almost 100%, but we would have a lot more false negatives and as a result less training data available for fine-tuning.
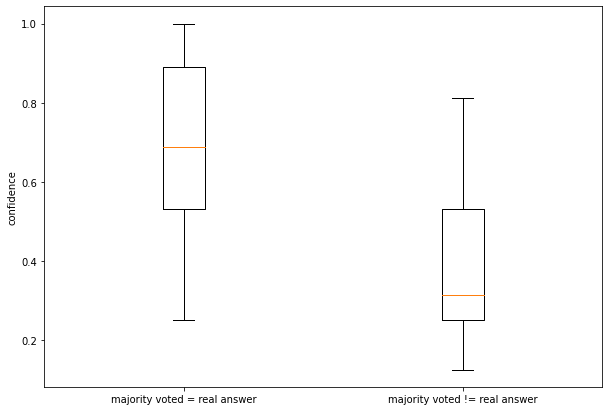
Due to budget constraints, I only generated training data using 100 randomly sampled, unlabeled GSM8K questions. I obtained a bit less than ~2K question-answer pairs (~89% accuracy) that I used to fine-tune Curie through OpenAI’s API. Unfortunately, the fine-tuned Curie barely performed better (0.2-0.5%) than the original Curie model. The minor improvement cannot prove that the fine-tuned Curie performs better than the base model.
Generating training data using Davinci is quite expensive. It costs around $0.23 to generate and train with 20 training data (and with only 89% accuracy). Since it’s unclear how much training data is needed so that we can observe a statistically significant improvement in Curie’s performance, I decided it might not be feasible to scale this project.
Further Plans & Ideas
Here’s what I would explore using the pipelines I created if I have enough budget:
I would exponentially scale the amount of training data to determine how much training data is required to improve Curie’s performance on GSM8K.
I would improve the accuracy of the generated answers by thresholding at a higher confidence level and finding a relationship between training data accuracy and fine-tuning effectiveness.
I would explore if there’s a plateau at which Curie’s performance will no longer improve given the generated training data, and where that plateau is.
I would try fine-tuning smaller models like Babbage and see how much training data is required for smaller models to have a statistically significant improvement on logic tasks
If one-day OpenAI allows us to fine-tune Davinci, I would want to explore these questions
Instead of using the questions in GSM8K, ask Davinci to generate more questions and generate responses for those questions. Where does performance plateau with these generated questions and generated completion pairs?
Have Davinci recursively improve itself: generate completions using given training questions without ground truth labels, fine-tune, generate new questions and completions, fine-tune, repeat. How far can we get with LLM’s recursive self-improvement? Does it generalize to out-of-domain tasks?
If you’ve read all the way to the end, I truly appreciate you! This is among one the first research papers I read, and the first one I tried to implement. Sometimes, I look at my peers who’ve started ML research in high school or who’ve already published papers at major conferences and I’d think that I am way too late to the game. However, that’s not a reason not to start now - and the same thing applies to anything that you’ve been wanting to learn!